


We hear this all the time and know of enterprise sized software companies working to build their own internal AI troubleshooting platforms. We all knew the costs of GPU processors would be dropping, but not so dramatically as indicated during a keynote from the GPU technology conference (GTC) on March 19, 2025. NVIDIA CEO Jensen Huang introduced NVIDIA Dynamo, an open-source operating system designed to enhance the efficiency and scalability of large language models in AI factories. Dynamo optimizes GPU resource allocation, leading to faster AI processing, reduced costs, and improved real-time inference capabilities.
By integrating Dynamo with the upcoming Blackwell Ultra NVL72 processors, NVIDIA aims to achieve a 40-fold increase in AI factory performance compared to the previous Hopper architecture. In fact, in combination with the new processors this will turn into a 50-fold increase in performance processing tokens per second over the previous H100 GPUs. According to Nvidia, all these components will be available “in the second half of 2025”.
As today, such systems will be utilized to support both the largest and smallest workloads. This means this 50-fold increase in token processing will be available to most projects. As an estimate of how this will affect costs, lets look at cost per 1k tokens processed over the past nine years:
Please note: The tokens-per-second values are approximate and can vary based on specific workloads, configurations, and optimization levels. This is the reason for the lower and upper bound for this estimate.

The above chart was built from the following data:
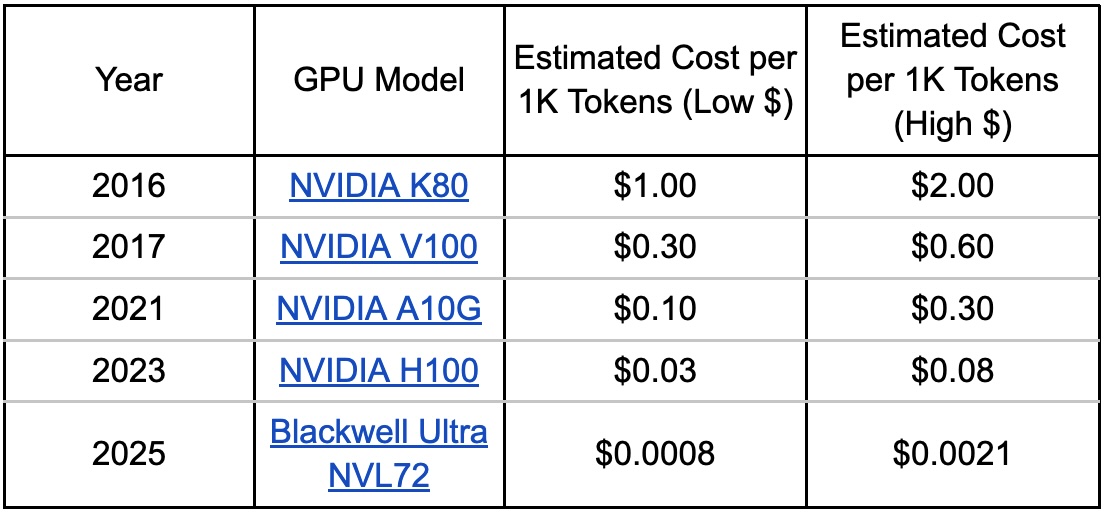
Only when we see the actual performance of each of the GPUs mapped do we see the reasoning for this last estimate of token cost for the Blackwell and Dynamo architecture (about 35X decrease) from H100 GPUs.

As mentioned, this is a 50-fold increase in performance compared to the previous generation H100. From estimates this could yield a 35X reduction in street costs by providers like AWS, Lambda and others.* Regardless, the trend is clear prices will drop considerably to match the performance bump.
*This reflects matching historical margins from these providers.
What could this translate to in pricing from OpenAI?
For Open AI to see the estimated discount over today’s cost per 1M token for Open AI:

This is an estimate of what OpenAI might charge based on historically what they’ve charged based on the performance / cost of running H100 clusters. The above may not reflect what they WILL charge per 1M tokens processed. In this estimate, we can see a 2X price reduction.
Build vs. Buy Primer
From the above, we’ve created a primer of things to consider to help in analyzing this “buy vs. build” dilemma.
1. Introduction
Everyone is trying out and working to add agentic AI systems (like large language models running AI agents) to generate significant business value. Recently, there have been many players like ourselves introducing agentic AI troubleshooting that reduces the time on-call engineers must spend debugging and repairing incidents.
Why Buying an Agentic AI to automate troubleshooting Is Still Cheaper Than Building One
Agentic AI—encompassing large language models, autonomous agents, and other advanced machine-learning systems—promises tremendous value for organizations.Troubleshooting using agentic AI goes well beyond collecting logs and metrics: it requires robust tracing, anomaly detection, and compliance monitoring across complex, distributed workflows.
Companies evaluating their options often wonder whether it’s better to build a custom observability platform or buy a specialized solution from a vendor. In this post, we’ll illustrate why, even with dropping GPU costs and vendor subscription costs of ~$50,000 per year, the economics still favor buying a managed observability solution versus building your own.
2. The Challenges of Observability and troubleshooting using Agentic AI
Complexity of Distributed Pipelines
Modern production software typically spans microservices deployed on kubernetes clusters that scale up and down on demand. A robust observability platform must handle massive data streams and dynamically correlate logs, metrics, and events in real time.
High-Performance Requirements
Modern AI requires access to high-end GPUs for inference, if using in-house models, or using APIs from model providers like OpenAI, which can get expensive unless tuned properly.
Specialized Skills & Maintenance
Building and maintaining an AI observability platform internally demands ongoing expertise in ML, GPU usage, distributed systems, data pipelines, plus compliance requirements.
2. Cost Analysis: Build vs. Buy
Let’s imagine a mid-sized to large enterprise receiving many thousands of alerts each month which turn into many hundreds of incidents. Here’s how costs might compare in Year 1 if you choose to build your own observability platform or buy a fully managed solution.
2.1 Building Your Own Observability Platform
Key Assumptions:
Renting GPUs from your hosting provider such as AWS for real-time analytics or large-scale inference, at $200/month each if the above projections hold at ~35X cheaper than the current H100s.
1. Engineering Costs
6 data/platform engineers at $150,000/year → $900,000 total annual salaries.
If 50% of their time in the first year goes toward building your observability platform, that’s $450,000 allocated to the project.
2. GPU Rental from your hosting provider.
Access to Blackwell NVL72 GPUs at $200/month → $2,400/year.
4. Maintenance Staff
Beyond the initial build, you’ll likely need at least 1- 2 dedicated FTEs to maintain and improve the observability platform.
That’s $300,000 per year in salaries.
5. Opportunity Cost
Diverting engineering talent away from your products core AI features can slow innovation. If your AI projects generate around $5M in annual revenue, losing 20% of that due to reduced feature velocity is $1M in potential opportunity cost.
Year 1 Build Total
Engineering Build: $450,000
GPU Rental (AWS): $2,400
Maintenance Staff: $300,000
Opportunity Cost: + $1,000,000
--------------------------------------
Year 1 Build Total: = $1,752,000
The GPU rental becomes a rounding error, but the “build” scenario still tallies up to almost $1.8 million in Year 1.
2.2 Buying a Fully Managed AI Platform for Observability
Now consider a specialized vendor offering agentic AI for observability and troubleshooting for $50,000 per year.
1. Platform Subscription
$50,000 annual fee for an enterprise plan capable of handling ~200 million inferences/month.
This might include GPU-backed analytics on the vendor’s backend.
2. Implementation & Integration
This will be part of the annual subscription fee.
3. Maintenance Overhead
The vendor handles ongoing patches, upgrades, and platform improvements.
Internally, you might devote a partial FTE (0.25 or 0.5) to manage the relationship and handle minor customizations → $25,000.
4. Opportunity Cost
Effectively zero, as your team continues to focus on building and refining AI models that produce direct business value.
Year 1 Buy Total
Platform Subscription: $50,000
Maintenance Overhead: $25,000
Opportunity Cost: $0
---------------------------------
Year 1 Buy Total: $75,000
At $75,000, the cost of a fully managed solution is a fraction of the $1.8 million+ you’d spend building it yourself—again, even considering GPUs will become a rounding error for such a a project. The real cost is your time and staff.
4. Further Considerations
Multi-Year TCO
Year 1 costs tell only part of the story. Over multiple years, “build” costs will accumulate as your data volume grows, GPU rental needs increase, and your platform must be updated for new AI workloads.
Time-to-Value
Standing up an AI platform for observability platform from scratch can easily take 6 to 12 months before reaching robust functionality. A managed solution can be operational in days or weeks, letting you realize immediate benefits in reliability and avoiding incidents and outages.
Focus on Core AI Innovations
Your engineering teams are likely more valuable improving your AI products than reinventing the observability wheel. By buying, you keep your core teams focused on features that directly generate revenue or strategic advantage.
5. Conclusion
Even if you don’t buy physical GPUs—and instead rent them for observability and inference—building your own agentic AI observability platform still entails hefty engineering, maintenance, and opportunity costs. Meanwhile, a vendor offering a subscription plan in the neighbourhood of $50,000 per year can provide a comprehensive observability suite, ensuring rapid deployment, minimal overhead, and seamless compliance updates.
The financial math is straightforward:
• Build: ~$1.8 million in Year 1, once you factor in engineering labor, maintenance staff, and lost opportunity.
• Buy: ~$75,000 in Year 1, with negligible opportunity cost and minimal internal overhead.
For most organizations, these numbers make the decision to buy a managed solution very clear, freeing up resources to focus on what truly matters: creating, improving, and scaling their own software products ad systems that drive their core business goals. As GPU costs fall precipitously, deploying a subscription from a vendor focused on this type of solution will become an even better value with their feature set growing while their prices drop.
Call to Action
1. Calculate Your Own TCO: Gather real figures for salaries, GPU rentals, licensing fees, and AI revenue projections to see how building vs. buying compares in your specific context.
2. Evaluate Managed AI Observability Platforms: Many vendors offer flexible pricing, advanced features, and 24/7 support that can drastically lower your total cost of ownership. Ask them for their annual or per alert/ incident pricing based on your company.
3. Prioritize Core AI Innovations: By choosing a ready-made platform, you can redeploy your skilled engineers to build cutting-edge AI solutions that directly enhance your competitive edge and bottom line.
About Relvy
We’ve paired our cost effective custom tuned language models which operate at 1/200th the cost of existing foundational models to make 24/7 agentic AI monitoring and debugging a reality. Get started instantly and see how Relvy can drastically reduce debugging time and costs, transforming your engineering processes today.

